Introduction
When working with data structures, computer scientists are really only after one thing: constant time complexity.
Whether you have one item or one million, a constant time complexity guarantees that the algorithm's runtime is a constant number, independent of the input size.
So far, arrays and linked lists have proven to take far from constant time, and even hash tables have some drawbacks in terms of their efficiency.
Today, we'll explore a new data structure called tries (pronounced trees), which may lead us one step closer to that pinnacle of algorithmic efficiency: constant time complexity.
What Exactly Are Tries?
Much like how hash tables can be a culmination of arrays and linked lists, tries combine pointers, arrays, and structures (structs).
Tries are almost like maps that, when followed successfully, lead to the data we're looking for.
Also, unlike with hash tables, tries should (ideally) always have different "keys," meaning two different pieces of data can never be found at the same path.
This may all sound a bit abstract, so let's take a look at an example.
Conceptualizing Tries
You can think of a trie as its homophone: a tree, or rather, an upside down tree.
At the very top, there is a root "node"
made up of an array and a pointer to another trie
This root points to different nodes, like leaves, that continue down the tree
Suppose we made a trie to store a collection of words.
The root node and leaf nodes would contain
an array of 26 characters, representing the letters in the alphabet that our word can contain
a pointer to another trie (another leaf)
Let's define our trie data structure now.
typedef struct Trie
{
// stores the word as a string
// will be empty if path isn't completed
char word[26];
// points to another trie array
struct Trie* paths[26];
} trie;Let's start constructing this trie visually...
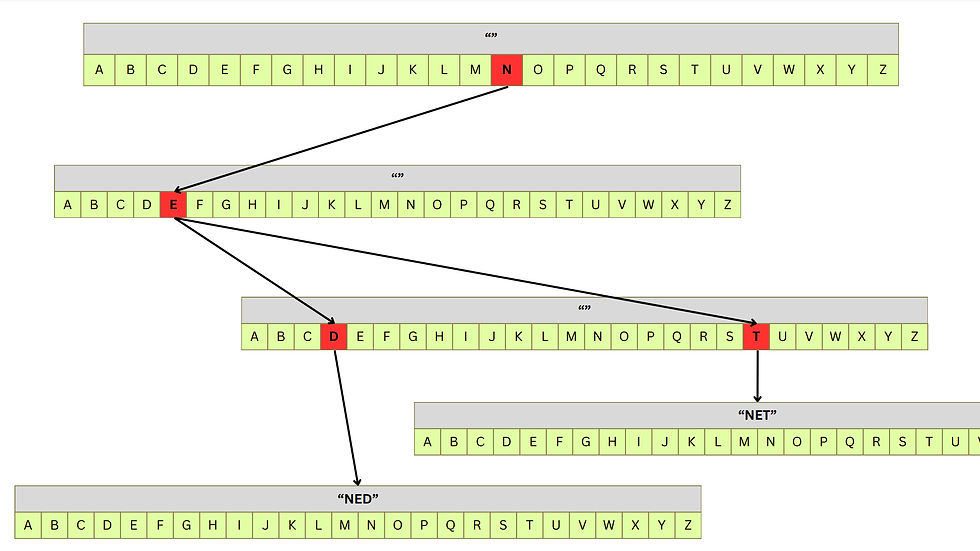
At the very top is our root node storing an empty string in our "word" char array.
Let's say we want to store the word "NED"
malloc a new 'leaf' node for the letter E to go in
have N point to the next leaf node
repeat the same steps for all letters
finally, malloc a new node for the final word itself, storing "NED" in the word array
In this way, our key is guaranteed to be unique because our key is our data itself (and each word is unique!)
If we were to store "NET," we would simply follow the same route from N to E, but then utilize the T in the former node and finally store the word itself in a new node
Searching Through Tries in C
Just like we did with linked lists, traversing a trie would require a separate pointer we can call trav (because we don't want to change the root node.)
Since we only have access to the root pointer, trav will point to the root at first, and make its way down the trie.
if each "letter" or "route" is opened (highlighted in red), then we can continue down the path
if not, our word is not within the trie
finally, we must check if there is a node storing the word itself
simply checking if the paths exist does not account for words existing within words
ex: checking if all paths were open for "CAT" would not guarantee that the path doesn't continue to a parent word like "CATCH"
Final Thoughts
Hopefully this guide to tries has given you a bit of context of what they are and how they can be used. Thanks for reading!
Comments